

If I gave you the following nanodump command, how accurately can you predict how your EDR product will react to its execution?
nanodump --duplicate --fork --write C:\Windows\Temp\invoice.docx- Will your EDR product prevent the successful execution of this command?
- Will your EDR product generate an alert in a way that a human is likely to review and triage it in a timely manner?
- Will your EDR product generate any non-alert telemetry that can be queried by analysts at a later time? Is the available data meaningfully useful for common investigation tasks?
When confronted with this question, most infosec professionals put on their most puzzled thinking faces and begin going down the rabbit hole of various “it depends on…” statements. The resulting answers range from “I have no idea” to a certainty that the detection rules and preventative controls they authored work in a particular way. To these people’s credit, these self-authored solutions are often impressive in their own right. But the internal logic of their respective EDR products remains too opaque to confidently predict how they will respond to a specific command. They may understand what this command does under the hood and how it interacts with the operating system, but there are too many variables at play and too little information available to predict how their EDR product will react to those actions.
An infosec team’s entire goal is to have some defensible level of certainty that our employers’ IT environments are adequately secured. Our job is not to entirely prevent every instance of unauthorized access to those environments. Our job is to do what is necessary to feel certain that what we do everyday is making it less likely that unauthorized access can result in some tangible negative impact to the business.
That certainty we seek stems from making predictions about the nature of offensive tradecraft and the way that tradecraft would interact with our current defensive controls. But if a key part of our security operations arsenal is largely unpredictable, how certain can we really be?
The Issue With Inheritance
In almost all of the organizations I’ve worked with, EDR products have moved beyond a “must have” control surface. They are often so central to visibility and instrumentation on Windows systems that an EDR product’s capabilities and output are the fundamental building blocks of the organization’s detection, response, and remediation processes. These organizations still certainly have all the other hallmarks of a layered defense — their SIEM, native controls, network controls, NDR, IAM solutions, secure email gateways, etc. However, your average security operations sub-org relies on EDR to prevent and/or detect any malicious software that ends up on a workstation or server when the largely vendor managed solutions left of initial execution have already failed. Beyond that, EDR is often the source of truth for investigating any alerts that do end up getting presented to an analyst.
EDR is simultaneously the lock on the bank vault, the CCTV system, and the armed guard waiting to respond to a bank robbery. Yet we often can’t predict if the vault will be locked, the CCTV will save the footage that implicates a robber, or if the armed guards will draw their weapons in a hypothetical robbery.
But it all seems to be working.
Your SOC analysts are busy with a queue full of alerts and you have a few examples of them detecting and remediating an active compromise to show off. You have lots of nice pie charts and dashboards that show a ton of stuff happening. You have several really smart people writing their own rules in the vendor’s proprietary query language to buttress your very expensive EDR product. You’re focused on automating triage and response tasks these days, rather than on core questions of observability and the efficacy of existing detection rules. Your MITRE ATT&CK Matrix dashboard is well color-coded. You’re a mature organization now.
If we move past the aggregate metrics and dive into specific hypotheticals, our confidence begins to melt away. When we think about the causal relationship between some specific command and an action taken by an EDR agent in response, we quickly realize that we’re not totally sure what exactly it can see, how it determines if a given action is malicious, or under what conditions it might no longer “deal with it” for us. Despite the uneasiness, this all seems to be working so far.
A lot of time and effort is spent on making predictions about the efficacy of our defensive posture based on those aggregate metrics that fall away so quickly when confronted with a specific example. I would argue that these efforts are often at least partially ritualistic in nature.
We should obviously strive to understand the overarching trends that show us how our security operations teams are spending their time and what the observable output of that effort is. The trouble comes from turning these dashboards and metrics into a subjective statement about whether your organization could weather a normal means attack.
Because we both heavily rely on EDR products for security operations and don’t have a good way to understand their limits and constraints, we are forced to inherit all of the design decisions that went into those products. More specifically, we are inheriting the predictions that the authors of those products made about:
- the nature of the offensive tradecraft their customers are likely to have used against them,
- how best to observe that tradecraft,
- how best to detect that tradecraft,
- when it is best to take some preventative action in relation to that tradecraft, and
- the likelihood that a specific action is evidence of a larger incident and an alert should be presented to an analyst.
The developers and researchers that determine how our EDR products make decisions about these questions on our behalf implicitly provide those answers in the code, rule sets, and design decisions that they bring to life. We simply inherit those answers, whether good or bad, when we use their products to defend our IT environments. This could be great for us or it could be very bad, but most of us couldn’t really tell you either way.
So if EDR products are massively important to security operations, but also largely opaque to most of their customers, what are we doing to mitigate the uncertainty they introduce when estimating the efficacy of our security posture?
Mostly rituals.
The Grimdark Present
If you are (or have worked around) a mega nerd, you may already be familiar with the concept of the “Machine Spirit” from the Warhammer 40K universe. If not, I will provide some context (don’t get mad at me for getting nerd stuff wrong).
40,000 years in the future, humanity has expanded across the galaxy with the help of a strangely decrepit looking, shadowy, and cultish army of adherents named the Adeptus Mechanicus. The Adeptus Mechanicus maintain the Empire of Man’s vast fleets of spaceships and war machines, but exclusively using technology that was invented tens of thousands of years ago. This technology and its inner workings has largely been lost to time, but the Adeptus Mechanicus travels across space destroying whole civilizations in their quest for samples of this old technology and information about it. To them, all technology is a direct extension of, and gift from, the “Machine God”, making it’s modification an extreme form of heresy.
When a machine malfunctions of ceases to function entirely, the Adeptus Mechanicus believes that it is the result of the displeasure of its “Machine Spirit”. All maintenance and repair of the Empire’s war machines is a matter of ritualistically indulging the machine spirit as it exists in a given machine. There is no attempt to observe, document, and diagnose the inner workings of the machine — only ritual placation.

Much like the Adeptus Mechanicus, infosec professionals have lost their ability to peer into the inner workings of the machines that were built before them. We can’t quantify what kinds of predictions and decisions we’ve inherited from the creators of these machines and we are responsible for testifying to their efficacy. In this light, it makes sense that we are in search of rituals to appease the machine spirit that lives inside of the security operations tech stacks we’ve built. It is meaningfully difficult to untangle the variables at play when answering the questions at the start of this post. It is only natural to seek out something to do that at least feels like it may be proving the point that what we’ve put in place is effective.
For the rest of this post, I would like to address a few questions related to all of this:
- What do these rituals look like?
- Why are these rituals ineffective?
- How do we define (and appease) the machine spirit in our EDR products?
The Tech-Priest In You

When security operations managers say they are having a hard time demonstrating the value of their teams, what they are really saying is that they struggle to enunciate exactly how their team’s daily efforts decrease the likelihood that an adversary could do damage to the business.
They are not wrong for being lost on this question. There are lots of ways to produce slides, spreadsheets, dashboards, reports and processes that seem like they prove all of your team’s efforts are effective and there is a short list of “gaps” to close. There are comparatively few ways that you can demonstrate that your current defensive posture is adequate because of a specific set of tasks your team completed.
This brings us to the first ritual that I see many security operations teams performing in an effort to generate a presentably coherent deliverable to show which techniques the SOC can and can not detect or prevent — The Rite of the Sanctified Hue.
The Rite of the Sanctified Hue
Tech-priests perform this sacred ceremony when they need to attest to the notion that “we’d be fine if xyz happened to us, right <your name here>?”. This hasn’t happened before (as far as you are aware), but how can you prove that it can’t happen?
Before a tech-priest can carry out The Rite of the Sanctified Hue, they must have already carried out the preparatory incantations to prepare their Matrix. The goal is to diagnose the current disposition of the machine spirits that inhabit a security operations program. To do so, the tech-priest presents some kind of stimulus that is representative of a MITRE-defined attack technique to the machine, which responds with some kind of interpretable, observable output. When this output appears to suggest that the machine is likely to detect and/or prevent this stimulus, the attack technique that the stimulus (test case) represents is imbued with the sanctified hue (green).
After repeating these incantations until the Matrix is sufficiently populated with green, yellow, and red boxes, the tech-priest is ready to perform The Rite of the Sanctified Hue itself. At the conclusion of the ceremony, a successful adherent will have a coherent story to tell about how their machine can detect and prevent the attack techniques used in all of the threat reports published this year.
The Rite is necessary because there are often several short-comings with the way that many of us go about using the MITRE ATT&CK Matrix — both in how we fill it out and in how we interpret it. If we don’t apply a little corporate ritual to the whole thing, the edges are a bit too rough to stomach.

Addressing the Machine Spirit
The amount of interpretation required to meaningfully use the MITRE ATT&CK Matrix makes it easy to foil the whole effort through a few seemingly innocuous missteps. To begin with, we need to select some subset of the currently listed attack techniques that are more worthy of our time than the ones we did not select. For the sake of argument, let’s assume that we did a good job of selecting attack techniques that represent “core tradecraft” that the majority of attackers have a hard time replacing (or are at least very likely to attempt in your environment).
At this point, things seem pretty simple. We’ve selected three MITRE attack techniques to prioritize and we have a well-defined scope for our detection efforts.
The next step is to identify known procedures for these techniques. The MITRE ATT&CK knowledgebase mentions a few common tools and some general descriptions of how these techniques work, but not enough to really determine which tools are meaningfully distinct from one another. After some googling, browsing through github repos, and asking around, we’ve come up with a short list of tools that seem to be distinct from one another but still achieve the same outcomes (as defined by the technique they supposedly represent).
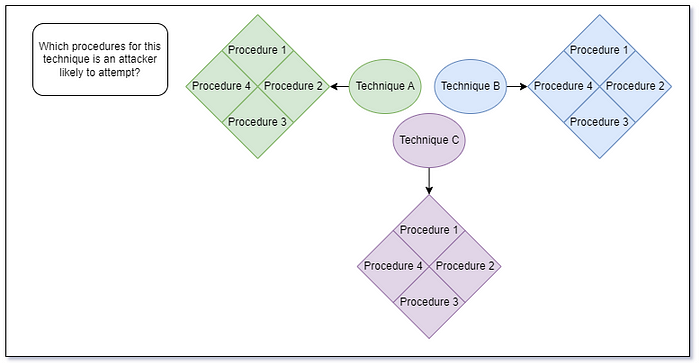
As we can see in the above diagram, our understanding of what kinds of offensive tradecraft we need to be concerned with is ballooning quickly. For each technique, we have some number of known distinct procedures. But this doesn’t really help us in determining how our EDR products are likely to respond to any of these procedures. If we want to answer that question, we need to determine what actually happens when these procedures are executed, what kind of telemetry could be produced, and what we think our EDR product will do with that telemetry. To approach this question, I define procedures as an ordered set of operations where an operation is an action targeting some object (ex. Creating a registry key, opening a handle to a securable object, modifying a file, etc.). I have written and spoken about this concept extensively if you would like more information about where this definition comes from and how it can be useful.
Once we’ve listed out the set of operations for each distinct procedure we identified, we can use some prior knowledge about telemetry generation to make assumptions about what kinds of telemetry might be available to an EDR sensor.
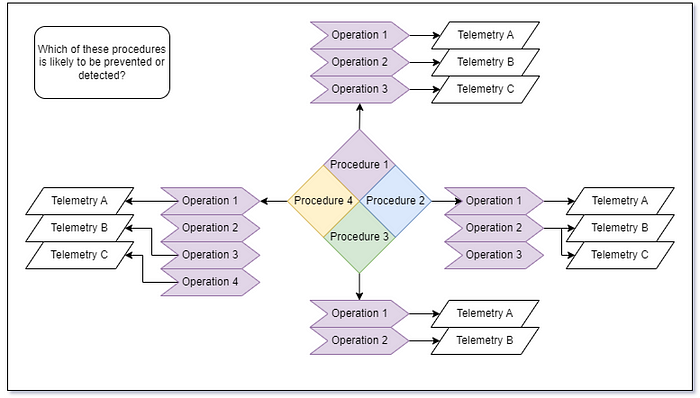
At this point, we have a decent idea about what kinds of telemetry each procedure might produce, but we’ve hit a predictive dead end. Our troubles here revolve around the fact that while we can predict the types of telemetry that are possible for a given operation in a procedure, we can’t know which telemetry generation mechanisms a given EDR sensor uses. Beyond that, we can’t predict which events from those sources are going to be ingested, evaluated, modified, or presented to end consumers in the product console.
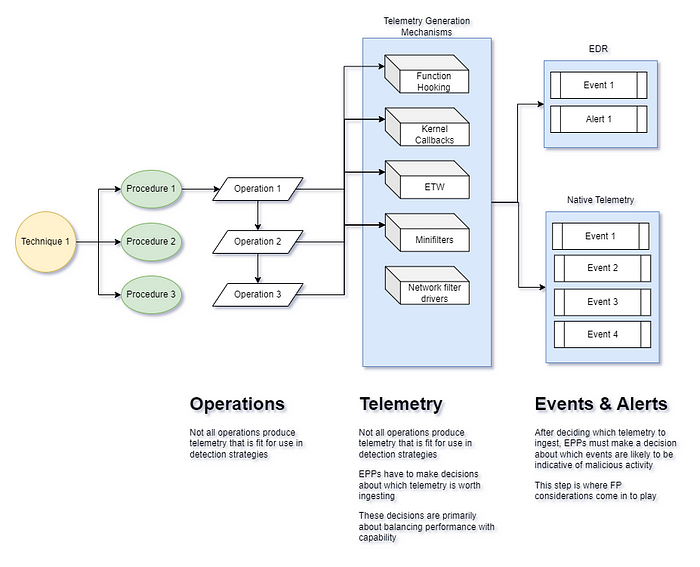
Under the hood, EDR sensor developers have a huge number of choices to make even when their assumptions about the nature of offensive tradecraft are 100% accurate. When making these choices, they have to contend with a wide range of pressures and requirements from technical experts, product teams, customers, and the limits of the systems their software will run on. Through no fault of the developers themselves, these pressures often distort the types of design decisions that go into the products we rely on. Beyond that, telemetry generation in Windows is an inherently complicated topic that touches complex, low-level components of the operating system.
Even if an EDR sensor does ingest events from one of the telemetry generation mechanisms above that applies to some operation we wish to detect, there is no guarantee that the information from that event is used to generate vendor alerts or supporting events accessible in the product console.
When we look at the explosion of assumptions we have to make to predict what offensive tradecraft is likely to be employed against us, combined with the huge number of unknown variables on the EDR sensor design side, it should be unsurprising that end consumers don’t have a lot of stable ground to answer the question that started this post. EDR vendors have to be right about the nature of offensive tradecraft and occasionally bend metal on a massive product to account for that tradecraft. That is a difficult task, but it only involves one set of complex predictions (those about tradecraft). End consumers have to make complex predictions about offensive tradecraft AND the nature of the EDR products that purport to address it.
Diagnosing the Machine Spirit
If you walk away from this post with one thing it should be that actually answering the question of what your EDR product is likely to prevent, detect, and observe is a question that exists entirely in the weeds. There are lots of ways to squint at a technique and say you are “covered”, but my assumption is that very few people are thinking through this problem in terms of what they can actually prove to themselves.
If we want to answer these questions in earnest, we need to actively test our EDR products in such a way that we present a series of varied stimuli (test cases) that are strategically designed to be comprehensive for a given technique. The word “comprehensive” does a lot of heavy lifting in that sentence, so let’s define what that means.
A comprehensive suite of test cases would address approaches to a given technique that represent:
- A distinct procedure: a unique set of ordered operations
- A varied procedure: the same set of ordered operations, but one or more operations is carried out in a way that impacts common detection and prevention strategies (ex. different function parameters that change values in critical telemetry, modifications to created artifacts, function call hierarchy trickery, etc.)
There will always be something you didn’t know about ahead of time that you have to add to your test library later. The point is not to be right all the time. The point is to painstakingly identify every variable that may lead to a successful evasion condition so that every new tool that purports to implement this technique can be granularly compared to known test cases in earnest. Expect to be proven wrong about possible tradecraft at some point and design a research process that is purpose built to adapt to shifting terrain.
When executed together, a good set of test cases are strategically varied to the extent that their success or failure tells you specific details about the detection logic powering your EDR product. Imagine a scenario where we have four test cases, each of which is for a distinct procedure of LSASS credential theft.
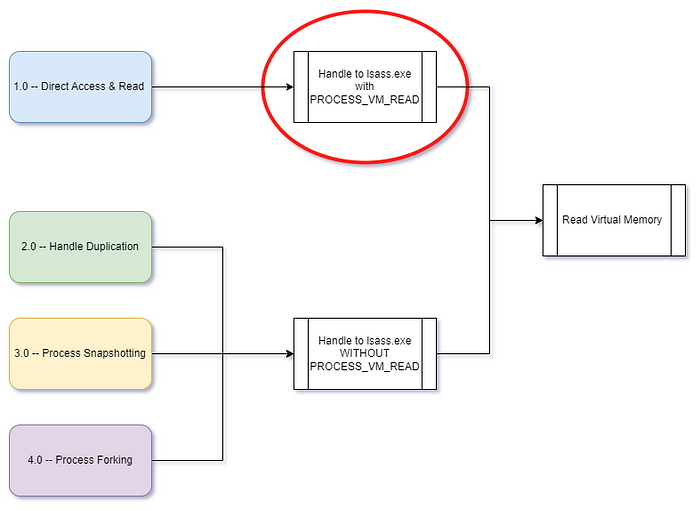
If we overlay their respective operations over each other, it is clear what the distinctions are by definition. If an EDR product only detects test cases #1 and #2, it is clearly focused on whatever operation is common between those two test cases but not included in test case #3. In this example, EDR is heavily focused on handles opened to lsass.exe with the PROCESS_VM_READ access right included. The other three test cases evaded detection because the handles they open to lsass.exe do not include that access right. Handle duplication does not need to open a handle to lsass.exe at all, but many tools that carry out this procedure end up doing so because lsass.exe owns a handle to itself that these tools attempt to duplicate.
This example is not contrived and this line of thinking has revealed a significant gap in the detection posture of top-of-the-line EDR products for LSASS credential theft. The important thing is not that we discovered a detection gap. The most important part of this whole process is designing our test cases in such a way that we can actually make assumptions about the nature of that detection gap based on the results. If we don’t have a structured way to classify the tradecraft represented by each test case, this all becomes a game of whack a mole where no particular tool or utility is a higher priority than any other tool.
So Now What?
Assuming you’ve followed my advice and abandoned ritual in favor of iterative, falsifiable testing practices, you probably have a bunch of test cases that your EDR product doesn’t seem fit to handle out of the box. To be frank, this post would balloon far beyond readability if I attempted to jump into detection engineering using well-curated test case execution results. Instead I will leave it at the unsatisfying notion that you address those gaps one by one.
The important part here is that because your test cases were well-defined and target specific “variables” in isolation, the gaps are very well-defined and easily observable. There are numerous data quality problems in the quest to fill in these gaps with your own detection logic, in addition to the often paltry set of telemetry that you can use when building custom detections within the walls of your EDR product’s web console.
But these problems are too widespread and nuanced to address thoroughly here, so I will leave you with some parting words that sum all of this up a bit:
You are likely reliant on an EDR product for the majority of your security operations tasks.
Detection and evasion is an inherently complex and uncertain problem set.
You do not have a reliable means to identify the assumptions the developers of that product made about those complexities when designing your EDR product.
If you want to address those assumptions, you need to test them in a comprehensive and strategic manner. The nature of those test cases will make or break these efforts.
If you do not conduct this kind of testing, you can not be certain that you are “covered” for a given technique.
Ritual will not save you.


