

Detection engineering, which can be summarized as the process of ensuring that some action occurs when a defined condition occurs, shares notable similarities with traditional software engineering, especially test-driven development (TDD). Both rely on the ability to lead development efforts with the end logic in mind, define a set of expected states at the completion of a function (or detection), account for different conditions that may induce a failure state, and routinely test code to validate our implementation against the desired end state.
This blog post aims to demonstrate how to apply a TDD workflow to detection engineering that allows us to know with certainty that our detections protect us against the target threat.
What is Test-Driven Development (TDD)
The dominant test design pattern in TDD is Arrange-Act-Assert (AAA) (the other being Given-When-Then), the steps of which are defined as:
- Arrange - Set up a specific state via variable declaration, object instantiation, and initialization
- Act - Invoke the logic to be tested by triggering some state change
- Assert - Verify that expectations about the logic were met given the change
In traditional software development, we’re often testing functions inside of our application. In the contrived example below, we have a function that is supposed to find the difference between the smallest and largest numbers in a list. Our unit test creates a collection of four numbers, calls our function to find the maximum difference, and ensures that the resulting value matches our expectations.
pub fn find_max_difference(list: &[i32]) -> Option<i32> {
if list.len() < 2 {
return None;
}
let mut max_diff = 0;
for i in 0..list.len() {
for j in i+1..list.len() {
let diff = list[j] - list[i];
if diff > max_diff {
max_diff = diff;
}
}
}
Some(max_diff)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_find_max_difference_sorted_asc() {
// Arrange
let list = vec![1, 2, 3, 10];
// Act
let result = find_max_difference(&list);
// Assert
assert_eq!(result, Some(9)); // Largest between 1 and 10
}
}Can you spot the flaw in our function? What happens if we introduce the following unit test?
#[test]
fn test_find_max_difference_sorted_desc() {
// Arrange
let list = vec![10, 9, 5, 3, 1];
// Act
let result = find_max_difference(&list);
// Assert
assert_eq!(result, Some(9)); // Largest between 10 and 1
}Our assumptions of how the logic would work given different situations was flawed when we designed our function. Our function only works when a larger number comes after a smaller number. It can’t handle strictly decreasing lists because the difference between a pair of numbers will always be negative, which is less than our starting value of 0.
In detection engineering, induction of similar failure states typically occur when:
- we make concessions necessary to productionize the detection (e.g., exclusions),
- our control(s) themselves fail in some way (e.g., not collecting the appropriate telemetry), or
- our understanding of tradecraft is insufficient to cover all variations of the target of our detection.
In all cases, leveraging a TDD approach can help us identify gaps and understand the states that can trigger a failure in our detection logic.
Applying TDD to Detection Engineering
Now that we’ve seen the power of TDD, let’s integrate it into our detection engineering workflow. The first step is defining the AAA pattern within the context of detecting threats:
- Arrange - Deploying our detection logic to the relevant controls, installing a test runner on relevant systems
- Act - Execute a test/tool/malware sample that introduces the stimuli that we wish to detect
- Assert - Evaluate our control(s) to see if it performed the desired behaviors (collected telemetry, produced a detection, or actively prevented the known-bad behavior)
Let’s step through each of these individually.
Arrange
The first step in the TDD workflow is to prepare our system for the test. In the context of detection engineering, this means:
- installing a test runner of some sort, and
- ensuring that our detection logic is implemented in our control(s)
Next, you must ensure they have a means to introduce your test stimulus on a host. In many cases, team’s opt to use an off-the-shelf C2 framework, such as Cobalt Strike, Mythic, or Sliver, to execute their tests. While these are all viable options from my own experience, they come with serious limitations.
These tools require setup and maintenance of your own infrastructure (C2 servers, redirectors/listening posts, payloads to get the agent on to the host), the perceived risk of dual-use tools (will the blue/purple team using the red team’s core toolkit lead to the framework specifics being the focus of detection vs. the techniques exercised via the framework agnostically?), and the inherent friction of needing to deploy a piece of malware on a set of (ideally production) systems.
The latter, we find, is actually the hardest problem to solve for many teams. This is because we need to test on a representative sample set of systems to truly assess our coverage of a test, which may be a relatively larger number compared to the handful of endpoints our team has full control over. This leads teams to deploy test runners in labs that are rough approximations of their production environment, which are not truly representative of their attack surface but rather a grouping of somewhat similar OS builds.
Quantifying a representative sample set is the topic of a future blog, but suffice it to say it is more than a few and getting an agent on them is a real problem for a lot of organizations.
Some of the ways that Prelude helps with this, along with the other issues outlined previously, is through infrastructure management and being “real software.” With Detect, for example, there is no C2 server, redirector, or domains to manage explicitly—we handle all of that through our platform. You don’t need to worry about burning one of your operational payloads to get a test runner on endpoints because our probe is a simplistic, single-function, signed application that meets our needs and can be allow-listed in antivirus/XDR without introducing new risk. Lastly, it is incredibly easy to deploy our probe as it can be deployed through an existing security control, such as Crowdstrike Falcon, through an MSI/RPM/DEB/PKG using your software deployment tool of choice, or run as an ephemeral process on Windows, macOS, or Linux. </shill>
The final task for us to complete prior to executing our test is to make sure that our detection rules/queries/policies are applied. These can be things like CrowdStrike IOAs, which would involve making sure that the IOAs are enabled and assigned to a policy which has been applied to our identified hosts. They can also be SIEM queries, which would need to be added to scheduled search. The goal here is to make sure that we’re not going to induce a failure due to our work not being applied. We’ll also likely want to iterate quickly if we do detect a failure in our logic, so knowing the location, contents, and state of our detections will be important.
Act
The next step in the workflow is executing our test in order to stimulate the defensive control and evaluate its performance against our expectations. This can involve things like executing a native utility on the endpoint, an offensive security tool, or a specific piece of malware. What to test largely depends on your team’s detection philosophy.
There are many competing ideologies around what you should test and seek to defend. These range from threat-based, where you are performing (nearly) the same activities as a known threat actor based on something like threat intelligence, to attack paths, where the team leverages some knowledge of a relevant chain of behaviors that represent an adversary’s potential sequence of actions inside of your environment. There’s also technique exhaustion, where the most relevant and impactful techniques in the context of your organization are comprehensively tested to ensure that you have complete, robust coverage against them.
Regardless of your approach, you will likely end up with some number of discrete tests that you would expect the control to observe, detect, or prevent. Depending on the types of detections you are building, the goal could be to detect the invocation of the tool (precise detections) or the underlying behaviors shared amongst two or more instantiations of the technique (robust detections).
Let’s say, for example, I wanted to ensure that I am protected against “Create or Modify System Process: Windows Service” (T1543.003). My test stimulus would include things like:
- sc.exe (create and config)
- services.msc
- SharpSC
- PsExec
- smbexec.py (Impacket)
- Direct registry modification
How these specific stimuli are executed is also a complex topic. There are many different execution modalities that we can leverage to introduce malicious test stimulus to an endpoint, ranging from simply running a command to complex shellcode injection techniques. For example, a security test inside of Detect that uses the comsvcs minidump technique to extract credentials from LSASS could look like this:
//go:build windows
// +build windows
package main
import (
Endpoint "github.com/preludeorg/libraries/go/tests/endpoint"
)
func test() {
Rundll32LsassDump()
}
func Rundll32LsassDump() {
Endpoint.Say("Attempting to dump credentials")
powershellCmd := "gps lsass | % { & rundll32 C:\\windows\\System32\\comsvcs.dll, MiniDump $_.Id prelude.dmp full }"
_, err := Endpoint.Shell([]string{"powershell.exe", "-c", powershellCmd})
if err != nil {
Endpoint.Say("Credentials dump attempt failed")
Endpoint.Stop(126)
return
}
Endpoint.Say("Credentials dumped successfully")
Endpoint.Stop(101)
}
func main() {
Endpoint.Start(test)
}Assessing what a “good” test looks like depends greatly on your testing philosophy. Whether you are interested in simply a means to introduce the desired stimulus to the system or in comprehensively evaluating the myriad ways in which that stimulus can be introduced to the system, the objective of this step is the same—make “boom” happen so that your defensive controls can take action.
Assert
The final stage of this workflow is the actual assessment of our defensive controls; did what we expect to happen, happen? There are broadly three categories of behaviors that we can expect a defensive control to exhibit when a test stimulus occurs:
- Observe - The control produced and collected telemetry relevant to the stimulus in a way that would allow us to hunt or build detections from.
- Detect - An alert was produced positively identifying the test stimulus as malicious and ideally qualifying it as the specific technique or threat.
- Prevent - The control actively stopped the test during execution after identifying a malicious condition, and ideally produced an alert notifying a human that some autonomous action was taken.
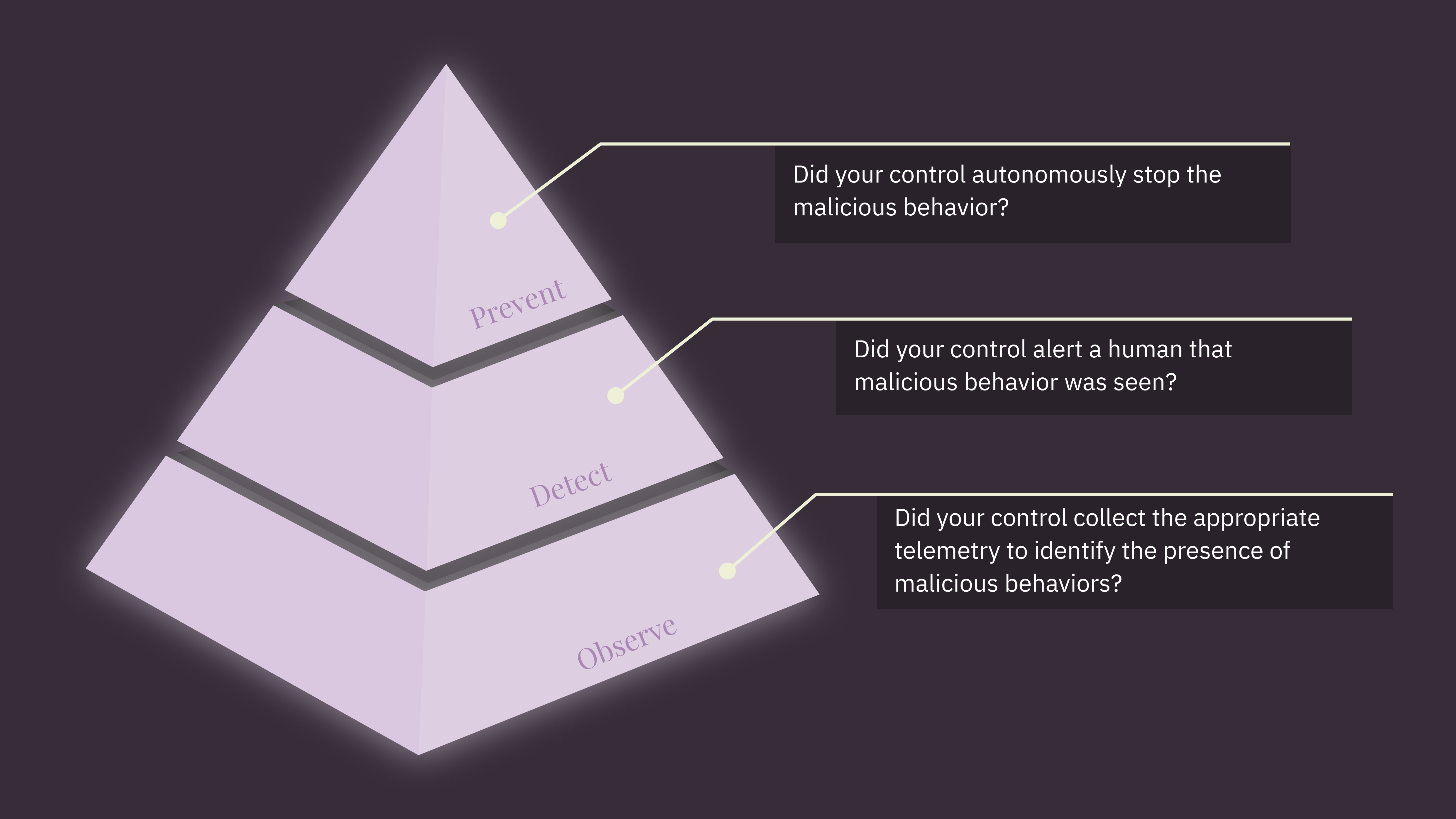
These three defensive behaviors form a 3-layer pyramid. Both detection and prevention are predicated on the fact that the control can see the malicious stimulus, so observed forms the base. Next, detections build on the telemetry produced through observation and says, “this pattern of behavior is indicative of evil and I need to tell someone.”
Lastly, prevention sits atop the pyramid representing the smallest number expected actions. Prevention is built on the idea that we have telemetry that we’ve identified as malicious, but that it is severe enough and/or we are certain enough about its nature that we are willing to take autonomous action to stop the source. It would be reasonable to assume that if we have the data to make a decision to detect, that we should be able to prevent the behavior in question too. While entirely possible, we have to remember that legitimate software does all kinds of crazy things that at surface level appear malicious, like browsers opening handles to LSASS when updating...
These false positives are what prevent us from turning every detection into a prevention. We don’t have the certainty needed in our detections, for one reason or another, to promote them.
To assess the defensive controls’ response to the stimuli, we typically manually interrogate the control itself. If we expect the control to have observed the test, we’d query the event feed for telemetry related to the test. If we expect it to be detected, we’d check the alert feed to see if one had been produced in response to our testing. If we expect it to have prevented the test, we can evaluate the alert feed again, looking for prevention-type alerts, and examine the test itself to determine if there was an early or unexpected error during execution.
We’ve automated this process in Detect in a feature we call ODP (for Observed, Detected, or Prevented) which allows you to integrate your EDR with our platform, define an expected result for a test, execute the test, and then automatically evaluate your controls’ response. This dramatically speeds up the ability to know how your control performed when exposed to known malicious stimulus and iteratively improve your posture through tweaks to detections, policies, or other levers inside of the control.
An Example
It may be helpful at this point to give a practical example of how a TDD-driven approach may look. While incomplete, this example will show the most important bits. In this contrived example, we have a function `detect_service_creation()` that simulates the upstream detection in your SIEM, EDR, or other control that we wish to test.
Our two test cases first check that our detection and test runner (probe, agent, etc.) are present. Then they will execute the core test stimulus. Each test executes the test stimulus in a different way depending on the nature of the tool it uses. Finally, the test case will validate that the test ran to completion and that the expected result of “detected” has been met. The latter not only checks that some detection has occurred, but that it is also tied to the specific test case.
/// Function that we will test
pub fn detect_service_creation(event: &Event) -> DetectionResult {
if let Event::RegistryValueSet(registry_value_set) = event {
if registry_value_set
.key
.starts_with("SYSTEM\\CurrentControlSet\\Services\\")
&& registry_value_set.value == "ImagePath"
{
return DetectionResult::ServiceCreation(registry_value_set.key.clone());
}
}
DetectionResult::Negative
}
#[cfg(test)]
mod tests {
use super::*;
/// The tests themselves
#[test]
fn test_detect_service_creation_sc() {
// Arrange
assert!(control.is_detection_live("ServiceCreation"));
assert!(test_runner.is_present());
// Act
let (result, timestamp) =
test_runner.shell("sc.exe create Prelude binpath= C:\\Windows\\System32\\Prelude.exe");
// Assert
assert!(result.is_ok());
let detections = control.get_detections("ServiceCreation");
assert_eq!(detections.count(), 1);
assert_eq!(
detections.latest().key,
"SYSTEM\\CurrentControlSet\\Services\\Prelude"
);
// make sure the the timestamp is within 5 milliseconds
assert!(detections.latest().timestamp = timestamp);
}
#[test]
fn test_detect_service_creation_sharpsc() {
// Arrange
assert!(control.is_detection_live("ServiceCreation"));
assert!(test_runner.is_present());
// Act
let (result, timestamp) = test_runner.exeute_assembly(
"SharpSC.exe action=create service=Prelude binpath=C:\\Windows\\System32\\Prelude.exe",
);
// Assert
assert!(result.is_ok());
let detections = control.get_detections("ServiceCreation");
assert_eq!(detections.count(), 1);
assert_eq!(
detections.latest().key,
"SYSTEM\\CurrentControlSet\\Services\\Prelude"
);
// make sure the the timestamp is within 5 milliseconds
assert!(detections.latest().timestamp = timestamp);
}
}When Tests Fail
A natural part of this process is seeing your expectations unmet right out of the box. Remember, though, that this is why we are testing. We can’t always trust what vendors tell us about the performance of their tools; we have to validate it for ourselves. The question of what to do when the control fails to meet our expectations largely depends on what the expected result was.
In cases where we expected the control to prevent the threat, it may be as simple as adjusting policies within the control, upgrading the action taken on a fired detection (even if that means triggering something external, such as a SOAR playbook), or by implementing something like a Crowdstrike IOA set to “prevent” to cover gaps.
In the event of a failed detection, this is where detection engineers step in. Assuming adequate telemetry was collected, our job is to find a way to extract the relevant bits, correlate them with other data points, and produce an analytic that, on positive match, will generate an alert in the control or a centralized system, such as your SIEM. The nature of this detection varies with the strategy of the team. If, for instance, they need to produce a large number of detections quickly, they may opt to create precise detections that target a very specific attribute of the test stimulus. If they have some breathing room, they may spend the resources crafting robust detections using the best telemetry available in the control to allow them to broadly detect the core of the test stimulus rather than creating detections that target only one instantiation.
For instances where a test was not observed, things get more complicated. There may be situations where there is an issue with the endpoint or control itself which prevents the data from reaching the collector service, but in many cases what we’ve found is that the telemetry we’d expect just isn’t captured. In these cases, our only real option is to either get that telemetry from a supplementary control (e.g., Sysmon) or to kindly ask the vendor to implement it in their sensor/agent. This may or may not happen at a pace needed (or ever) which is why this failure state is so frustrating for detection engineers. We just can’t do anything to improve our situation and have to tag it as a blind spot while we try to provide some kind of coverage using suboptimal data.
Wrapping Up
Depending on your expected outcome for a given test, the process from here is execute, evaluate, iterate, and go again until you get to a place that you’re comfortable with your coverage before moving on to the next target. This process of using expected results against a set of stimuli which adequately represents your desired coverage to improve the efficacy of your defensive controls feels like a superpower. You can end each exercise knowing for sure that your controls protect you against the threats most relevant to your business.


